The 3D Image -- Depth Maps
The simplest and most convenient way of representing and storing the depth measurements taken from a scene is a depth map.
A depth map is a two-dimensional array where the x and y distance information corresponds to the rows and columns of the array as in an ordinary image, and the corresponding depth readings (z values) are stored in the array's elements (pixels).
Depth map is like a grey scale image except the z information (float - 32 bytes) replaces the intensity information.
Fig. 32 Artificial depth maps
Fig. 33 Real depth maps
Why use 3D data?
An 3D image containing has many advantages over its 2D counterpart:
e.g Size (and shape) of an object in a scene can be straightforwardly computed from its three-dimensional coordinates.
Recent technological advances ( e.g. in camera optics, CCD cameras and laser rangefinders) have made the production of reliable and accurate three-dimensional depth data possible.
Consequently many three-dimensional data acquisition systems have been developed.
Methods of Acquisition
Laser Ranging Systems
Laser ranging works on the principle that the surface of the object reflects laser light back towards a receiver which then measures the time (or phase difference) between transmission and reception in order to calculate the depth.
Most laser rangefinders:
Structured Light Methods
Basic idea:
Moire Fringe Methods
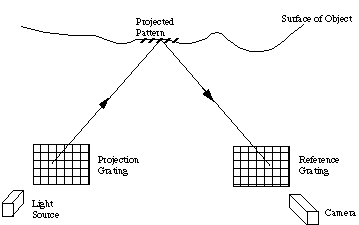
The essence of the method is that a grating is projected onto an object and an image is formed in the plane of some reference grating as shown in Fig. 34.
The image then interferes with the reference grating to form Moire fringe contour patterns which appear as dark and light stripes, as demonstrated by Fig. 35. Analysis of the patterns then gives accurate descriptions of changes in depth and hence shape.
Fig. ![]() A moire projection system
A moire projection system
Fig. 35 Moire fringe patterns
NOTE: Ambiguities arise in interrogating the fringe patterns.
Moire fringe methods are capable of producing very accurate depth data (resolution to within about 10 microns) but the methods have certain drawbacks.
Shape from Shading Methods
Methods based on shape from shading employ photometric stereo techniques to produce depth measurements.
Using a single camera, two or more images are taken of an object in a fixed position but under different lighting conditions.
By studying the changes in brightness over a surface and employing constraints in the orientation of surfaces, certain depth information may be calculated.
Methods based on these techniques are not suited for general three-dimensional depth data acquisition:
Passive Stereoscopic Methods
Stereoscopy as a technique for measuring range by triangulation to selected locations in a scene imaged by two cameras already -- further details on general stereo configurations in Books.
The primary computational problem of stereoscopy is to find the correspondence of various points in the two images.
This requires:
NOTE:
Active Stereoscopic Methods
The problems of passive stereoscopic techniques may be overcome by