

SHREC'14 - Shape Retrieval of Non-Rigid 3D Human Models
Introduction
The ability to recognise a deformable object's shape, regardless of the pose of the object, is an important requirement for modern shape retrieval methods. We have produced a new dataset for non-rigid 3D shape retrieval, one that is much more challenging than previous datasets. Our dataset features exclusively human models, in a variety of body shapes and poses. 3D models of humans are commonly used within computer graphics and vision, therefore the ability to distinguish between body shapes is an important feature for shape retrieval methods. The shape differences between humans are much more subtle than the differences between the shape classes used in previous datasets, but humans are able to visually recognise specific individuals. Successfully performing shape retrieval on a dataset of human models is therefore a far more challenging, but realistic task.
We welcome the submission of results of both general non-rigid shape retrieval methods, and specialised methods which are specifically designed to work with human models. We will evaluate general and specialised methods separately, to produce a fairer comparison of results.
To participate in this track, please register your participation by emailing d.pickup@cs.cf.ac.uk.
Organisers
David Pickup - Cardiff University, UK.
Xianfang Sun - Cardiff University, UK.
Paul L. Rosin - Cardiff University, UK.
Ralph R. Martin - Cardiff University, UK.
Zhouhui Lian - Peking University, Beijing, China.
Zhiquan Cheng - National University of Defense Technology, China.
Paper
The results of the track have now been published in the 3DOR paper available to download here.
Dataset
Our track uses two datasets, and each participant is asked to produce the results of their methods on both datasets individually. The first dataset is made up of “real” data, obtained by scanning real human participants. The second dataset is made up of “synthetic” data, created using DAZ Studio. The different characteristics of these two datasets may each provide their own unique challenges, and will ensure methods are not too finely tuned for just one type of data.
The models in the dataset do contain self-intersections in some of the poses. The models in the “real” dataset are closed, but the models in the “synthetic” dataset contain a hole for each eye, and a hole inside the mouth. Some of the meshes also contain a small number of high valence vertices, or inward facing triangles. Participents are free to preprocess the models if their methods can't deal with these properties. The file format of the models is .obj. We also provide a classification file (.cla) for each dataset (the format of a .cla is explained here).
The complete dataset is available to download here.
Please note that the data we provide must be used for research purposes only.
If you use our data, please cite us:
@inproceedings{Pickup2014,
author = {Pickup, D. and Sun, X. and Rosin, P. L. and Martin, R. R. and Cheng, Z. and Lian, Z. and Aono, M. and Ben Hamza, A. and Bronstein, A. and Bronstein, M. and Bu, S. and Castellani, U. and Cheng, S. and Garro, V. and Giachetti, A. and Godil, A. and Han, J. and Johan, H. and Lai, L. and Li, B. and Li, C. and Li, H. and Litman, R. and Liu, X. and Liu, Z. and Lu, Y. and Tatsuma, A. and Ye, J.},
title = {S{H}{R}{E}{C}'14 track: Shape Retrieval of Non-Rigid 3D Human Models},
booktitle = {Proceedings of the 7th Eurographics workshop on 3D Object Retrieval},
series = {EG 3DOR'14},
year = {2014},
numpages = {10},
publisher = {Eurographics Association}
}
Real Dataset
The “real” human dataset is built from the point-clouds contained within the Civilian American and European Surface Anthropometry Resource (CAESAR). The dataset is composed of 400 meshes, made up of 40 human subjects in 10 different poses. Half the human subjects are male, and half female. The point-cloud models were selected from CAESAR, and we employed the SCAPE (shape completion and animation of people) method [1] to build the 3D meshes, by fitting a template mesh to each subject. The poses of each subjects are built by using a data-driven deformation technique [2], which can produce realistic deformations of articulated meshes. We have retriangulated the models using the freely available software by Valette et al. (ACVD). This retriangulation method uses smaller triangles in areas with higher levels of detail. The size of the triangles is therefore not uniform. The resulting models are made up of approximately 15,000 vertices.
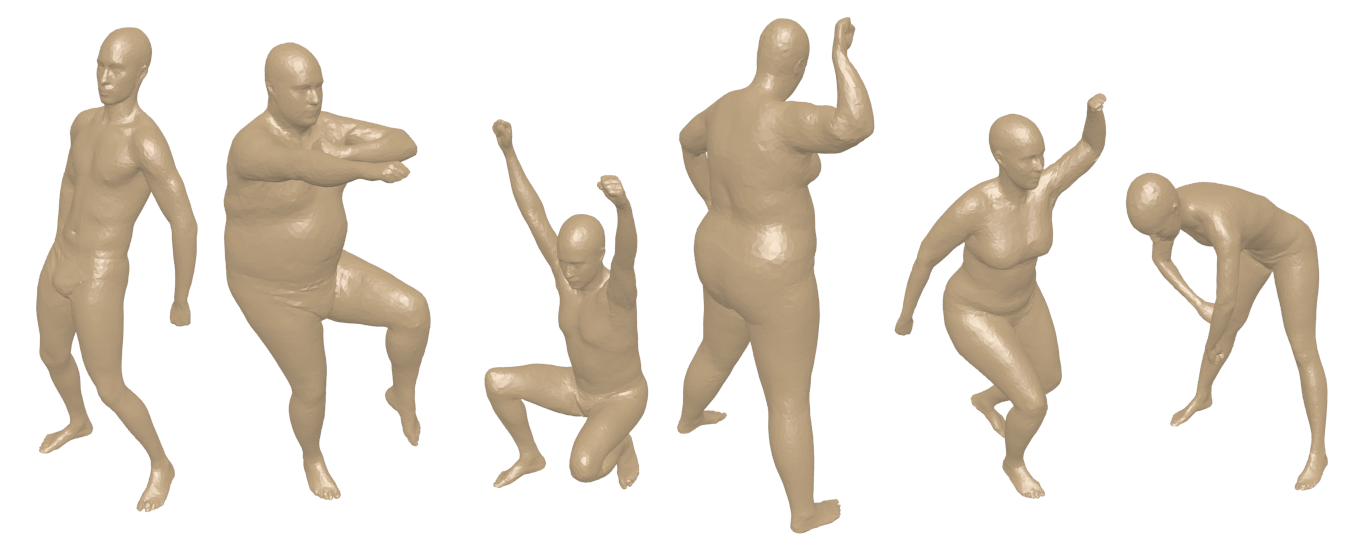
Synthetic Dataset
We have used 3D modelling/animation software to create a dataset of syn- thetic human models. The software we have used is DAZ Studio, which includes a parametrized human model, where the parameters control the models body shape. The dataset consists of 15 different human models, each with its own unique body shape. Five of these are male, five female, and five child body shapes. Each of these models exist in 20 different poses, resulting in a dataset of 300 models. The same poses have been used for each body shape, and objects are considered as part of the same class if they share the same body shape. The models are all retriangulated using the same method used with the “real” dataset. The resulting models are made up of approximately 60,000 vertices.
DAZ 3D have given us permission to distribute this data freely for research purposes. The data must not be sold or used commercially.
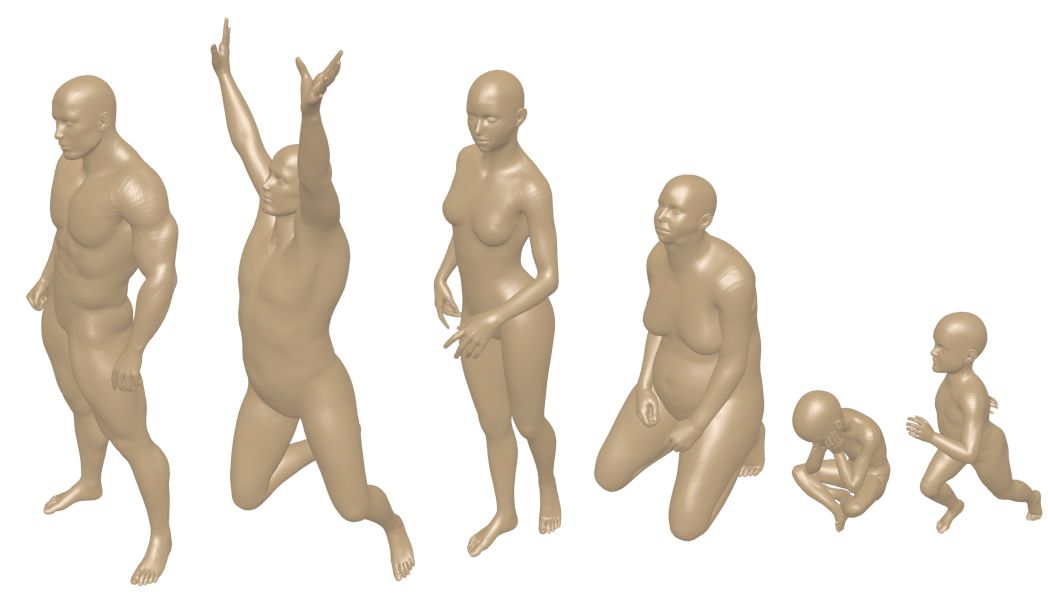
Task
There are two different types of retrieval tasks we will assess:
- Returning a list of all models, ranked correctly by shape similarity to a query model.
- Return a list of models that all share the same shape as the query model.
For both exercises each model in the database should be used as a separate query model. For the first exercise, for each query we ask the participants to provide a list of all the other models in the dataset ordered by their similarity to the query model. For the second exercise, for each query the participants are asked to submit a list of all the models which they classify as “the same shape” as the query model. The similarity of the models should be judged based on body shape, not pose.
Participants may submit results for just one or both of the retrieval tasks, depending on which task(s) their methods are designed to perform. We encourage all participants to enter a result for both. All participants must email all their results to d.pickup@cs.cf.ac.uk, along with a brief description of the methods used, by 8th February 2014.
Participants should produce results for both datasets described above separately.
Task 1 Submission Format
Participants should submit two files, each with all the query results for Task 1 for one of the datasets. The file should be named surname_method_T1_dataset.txt, where surname should be replaced with the first author's surname, method with the name of the method, and dataset with the name of the dataset (real or synthetic).
The models in each dataset are numbered from 0 to N-1, where N is the number of models in the dataset. Line i of the results file should contain the retrieval results of using model i as the query. So line 0 should contain the results for model 0, etc. Each line of retrieval results should list all the remaining N-1 models in the dataset, ordered by their similarity to the query model. The order should be from most similar, to least similar. The models should be separated by a space.
An example result for peforming Task 1 on the "synthetic" dataset is available here.
Task 2 Submission Format
Participants should submit two files, each with all the query results for Task 2 for one of the datasets. The file should be named surname_method_T2_dataset.txt, where surname should be replaced with the first author's surname, method with the name of the method, and dataset with the name of the dataset (real or synthetic).
The models in each dataset are numbered from 0 to N-1, where N is the number of models in the dataset. Line i of the results file should contain the retrieval results of using model i as the query. So line 0 should contain the results for model 0, etc. Each line of retrieval results should list all the remaining models in the dataset that are considered "the same shape" as the query model. The models should be separated by a space.
An example result for peforming Task 2 on the "real" dataset is available here.
References
[1] Dragomir Anguelov, Praveen Srinivasan, Daphne Koller, Sebastian Thrun, Jim Rodgers, and James Davis. Scape: Shape completion and animation of people. In ACM SIGGRAPH 2005 Papers, SIGGRAPH '05, pages 408-416. ACM, 2005.
[2] Y. Chen, Y. Lai, Z. Cheng, R. Martin, and J Shiyai. A data-driven approach to efficient character articulation. In Proceedings of IEEE CAD/Graphics, 2013.